ERD를 이용한 DB 모델링 - 발표자 : 용영환
- 시작하기전 주의사항
- 절대 정답이 아니다.
- 취업이나 승진을 보장하지 않는다.
- 발표자의 경험을 말해주는 것이며 그냥 발표자가 이런식으로 이해를 했다고만 받아들이자.
- 블로그 설계를 시퀸스다이어그램과 ERD로 그려서 네이버 합격?!(발표자의 경우)
- 면접이라는 순간에 임팩트를 남겨야하는데 말로 주저리하는것 보다 그려서 임팩트를 남기는게 낫다.
- 면접자는 매우 불리한 위치(어떻게든 자신을 표현해야한다.)
- 면접관이 설명을 하라하면 ERD를 그리면서 한번에 그리면 면접관이 심화 질문을 날리고 그것을 설명하면 좀더 면접을 잘 이끌어갈수있다.
- 물론 그것이 정답이 아니란 것은 알지만 그래도 남을 이해시킬때 말만 하는것보다 그림과 같이 설명하면 설득력이 올라간다.
- 회사를 입사해서 프로젝트를 진행할때 ERD를 슬쩍 그려서 책상위에 올려놓고 퇴근하면 지나가다 상사가 보았을때 점수를 딸수있다.(꿀팁!)
- 발표피피티
모델링이란?
- 현실세계에서 모델이란 옷을 입어보고 남에게 보여주고 사게하는 역활(대표성을 보여주는 객체 - 모델)
- 3D 모델링 - 라라크래프드(툼레이더)같은 캐릭터 역시 모델의 예이다.
- 결국 DB모델링은 데이터베이스를 만들때 데이타가 시각적으로 보일수 있도록 모델링하는 것.
- 소프트웨어를 해부하면 크게 동작과 데이터로 나눌 수 있다.
- 인간을 위한 소프트웨어 중에 데이터가 없는 소프트웨어는 없다.
- 소프트웨어 만들려면 본질을 이해해야한다. (프로그래밍이란 데이터를 제어하기위해 코딩이나 용법, 언어등을 사용한다.)
- 사전적 정의 - 모델을 보고 닮게 만드는 일, 우리말: 모각 - 이미 있는 조각 작품을 보고 그대로 본떠 새김.
- 모델링이란 우리가 소프트웨어에서 본질적으로 다루고 있는 데이터에 대한 모델을 만드는 과정이다.
- 소프트웨어 모델링이란 머리 속에 있는 생각을 누구나 볼 수 있게 본을 뜨는것. 객체나 DB를 그림으로 표현하는 것.
- 시간이 되면 UML이란 것도 찾아보면 도움이 된다.(시퀸스 다이어그램 등등)
- 모델링을 하면 좋은 점
- 시각화 시킨다는 것은 전체적 설계의 구조를 좀 더 명확하게 이해할 수 있게 된다.
- 남에게 자신의 소프트웨어의 의도를 잘 전달할 수 있다.(소프트웨어는 혼자 만드는 것이 아니기때문에 소통이 중요하다.)
- 모델링을 안해도 프로그램은 만들 수 있다. 하지만 하면 좀더 잘 이해하거나 소통을 좀 더 잘할수있다.
- 면접 볼 때 은근 좋다. 보여 줄 때 좋다. 만들고 나면 뿌듯하다.
- 자신의 생각을 표현해서 산출물이 나온다는것은 개발자에게 큰 영향을 미친다.
데이터베이스 설계 필요성
- 데이터를 보다 잘 다루기 위해서 설계가 필요하며 소프트웨어 전체에 영향을 미친다.
- 내가 만들고자 하는 소프트웨어를 제대로 이해하지 못하면 잘 만들 수가 없다.(목적과 의도를 정확하게 이해하지못하는데 소프트웨어의 품질이 낮아질수밖에 없고 성능이 낮아진다.)
- 개발자는 설계할때 한 곳의 성능이 떨어지면 다른곳에 영향이 가는것을 알아야하는데 ERD를 그리면 전체적인 구조를 파악하는게 좀더 편하다
- 테이블을 보여주는 것보다 ERD를 보여주는 것은 처음 개발을 시작하는 사람의 이해력을 높일 수 있다.
ERD를 그려서 얻는 이점
- 관계지향 (Nosql에서는 ERD를 그릴수 잇지만 안그린다.)
- RDBMS 데이터 설계가 쉬워진다.
- 프로그래밍, 코딩이 쉬워진다.
- 실무에서 정말 자주 사용한다. (스타트업 같은 경우는 잘 그리지 않는 경우도 있다.)
- 큰 서비스에서는 ERD만을 저장하는 Git과 같은 형상관리도구에 저장한다. (체계적으로 관리한다. 네이버나 삼성, 대기업들은 ERWin이라는 어마어마한 비싼 도구를 사용한다. - 개인은 이런거 필요없다.)
- 개인은 Mysql 워크벤치를 사용하는게 좋다.(Mysql 100% 지원)
- 조금 규모가 큰 회사에서는 ERD를 그리므로 알아두면 좋다.
- 무언가를 잘 할 수 있게되는 것은 동기부여가 된다.
ERD 도구
- ER-win - Oracle을 지원, 대기업에서 자주 사용
- MySQL Workbench - 전세계적으로 유명
- 다른 툴도 많다. (ERD Tool, DB Design tool 등을 검색해 보자.)
ERD 식별자
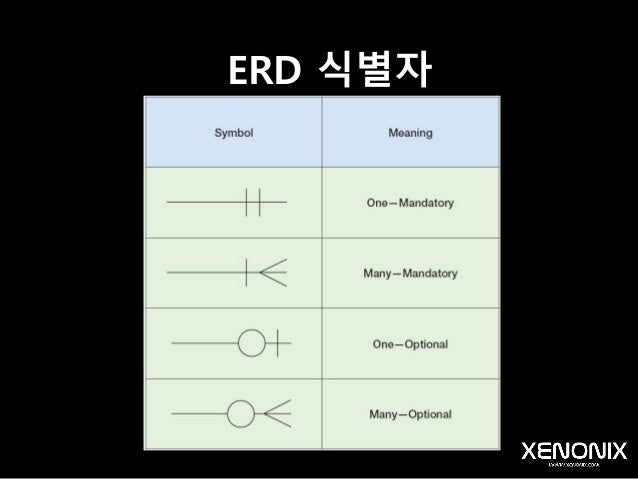
- 동그라미 없는 것과 잇는 것의 차이(동그란것은 Optional이라고 말한다.) - null값의 유무를 의미
- 실선과 점선의 차이는 Foreign키가 Primary key인가 아닌가의 차이.
ERD 표기법
- IE 표기법 - ER-win에서 지원(둘 다 지원한다.)
- Barker 표기법 - Mysql에서 지원
실습
- MySQL 워크벤치를 기준으로 진행한다.
- 스키마가 데이터베이스를 의미한다.
- 실선은 null값이 있으면 안된다.
- 점선은 null값이 있어도 된다.(optional)
- 선으로 연결된 것을 관계라고 한다.
- 선으로 연결된 관계가 있기때문에 관계형 데이터베이스 라고 한다.
- 용어
- Identifying Relationship : “식별 관계” - 실선, 점선
- Identifying <-> non Identifying
- Mandatory : 필수
- NULL을 허용할거냐 안할거냐의 참고 대상의 존재 여부를 의미한다.
- Cascade : 폭포란 사전적 뜻을 가지고 있으며 데이터베이스에서는 연쇄작용이 일어나는 것을 가르킨다.
- Foreign key options
- RESTRICT : 참고 테이블의 값의 변경을 거부한다. (일단 거절)
- CASCADE : 같이 삭제 또는 수정
- SET NULL : NULL로 변경
- NO ACTION : RESTRICT랑 동일한 결과 (나중에 거절)
- 정규화
- 관계형 데이터베이스의 설계에서 중복을 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화라고 한다.
- Identifying Relationship : “식별 관계” - 실선, 점선
- mysql은 소문자로 만드는게 관행
- mysql에 password 명령어가 잇어서 passwd라 한다.
- 테이블은 여러개의 데이터가 모여있기때문에 복수형이 컨벤션이다.
쇼핑몰
- 여기 설명은 제가 세미나가 끝난 후 복습하면서 제작한 과정입니다.
- 무조건 로그인이 되어야만 상품을 구매할 수 있는 쇼핑몰을 만든다고 가정하자.
- 로그인을 위해서는 유저의 정보가 있어야한다.
- 상품에 대한 정보가 있어야한다.
- 상품의 구매에 대한 정보가 있어야한다.
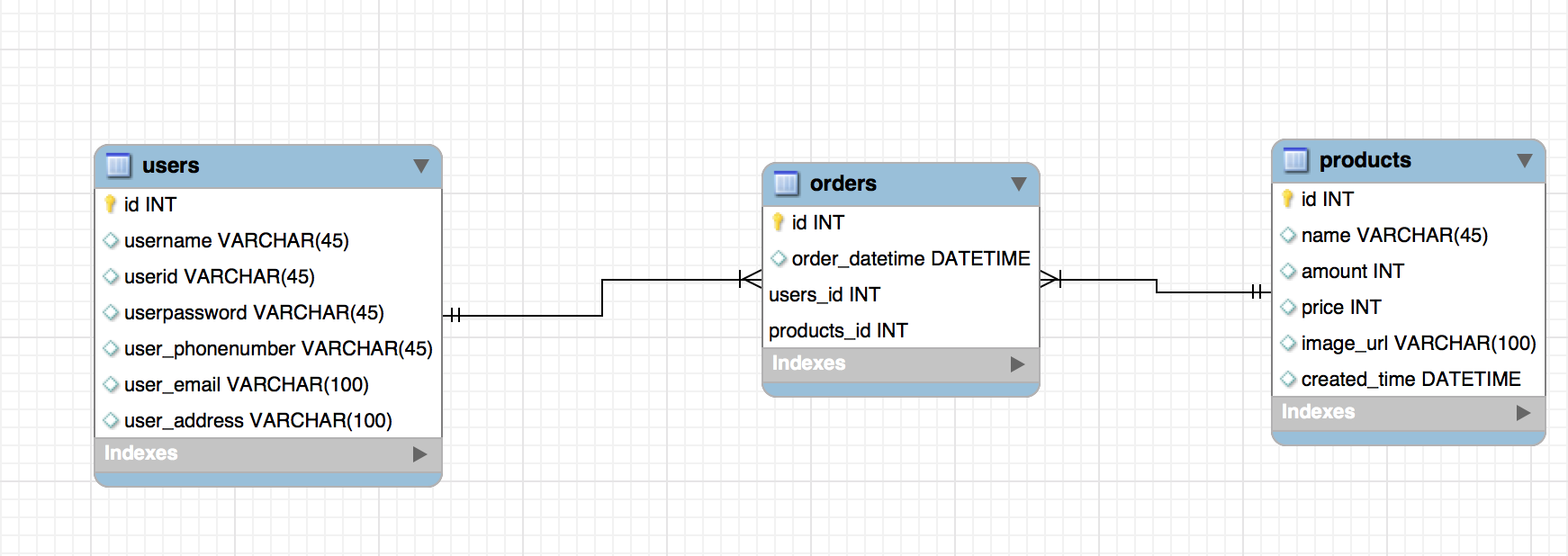
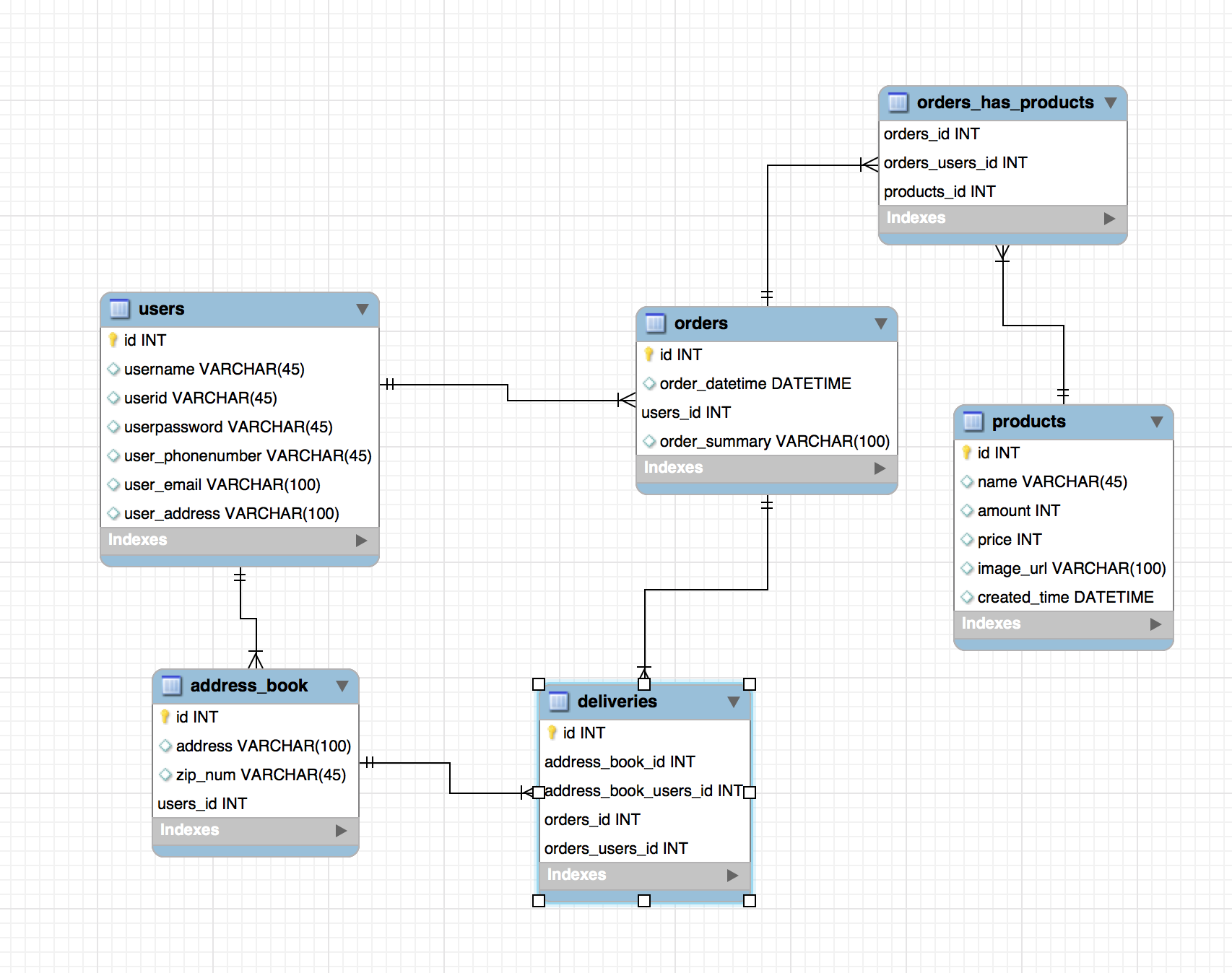
- 유저는 여러개의 주문을 가질 수 있기때문에 users와 orders는 one to many의 관계이다.
-
상품은 여러개의 주문에 주문되어질수 있기 때문에 products와 orders 는 one to many의 관계이다. 근데 이때 주문은 여러개의 상품을 가질 수 있다. 그래서 orders와 products를 many to many의 관계로 변경한다.
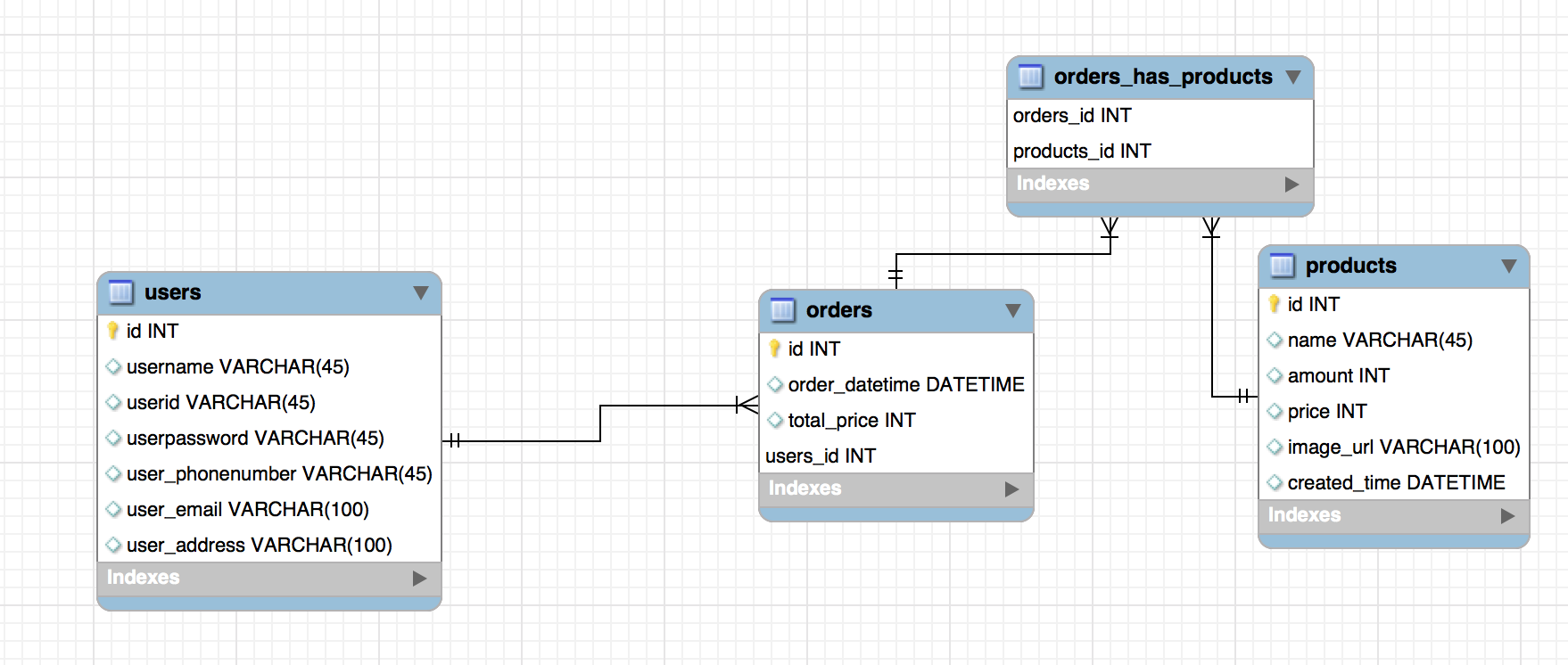
- many to many의 관계는 직접적인 관계를 연결 할 수 없기 때문에 orders_has_products 라는 두 테이블의 키를 가지는 테이블을 만든다.( 주문과 상품이 다대다의 직접적인 관계를 가질 시 주문은 여러개의 상품에 대한 정보를 가질 수 없고 상품은 각 주문에 대한 내용들을 가질 수 없기 때문의 각자의 키를 가지는 테이블을 하나 더 생성하는 것.)
- 여기까지만 다이어그램을 그려도 쇼핑몰의 윤곽이 잡힌다.
- 유저는 로그인을 해야 주문을 할 수 있다.
- 유저는 상품을 고르고 주문 목록에 넣을 수 있다(orders_has_products) - 장바구니의 역활을 하게된다.
-
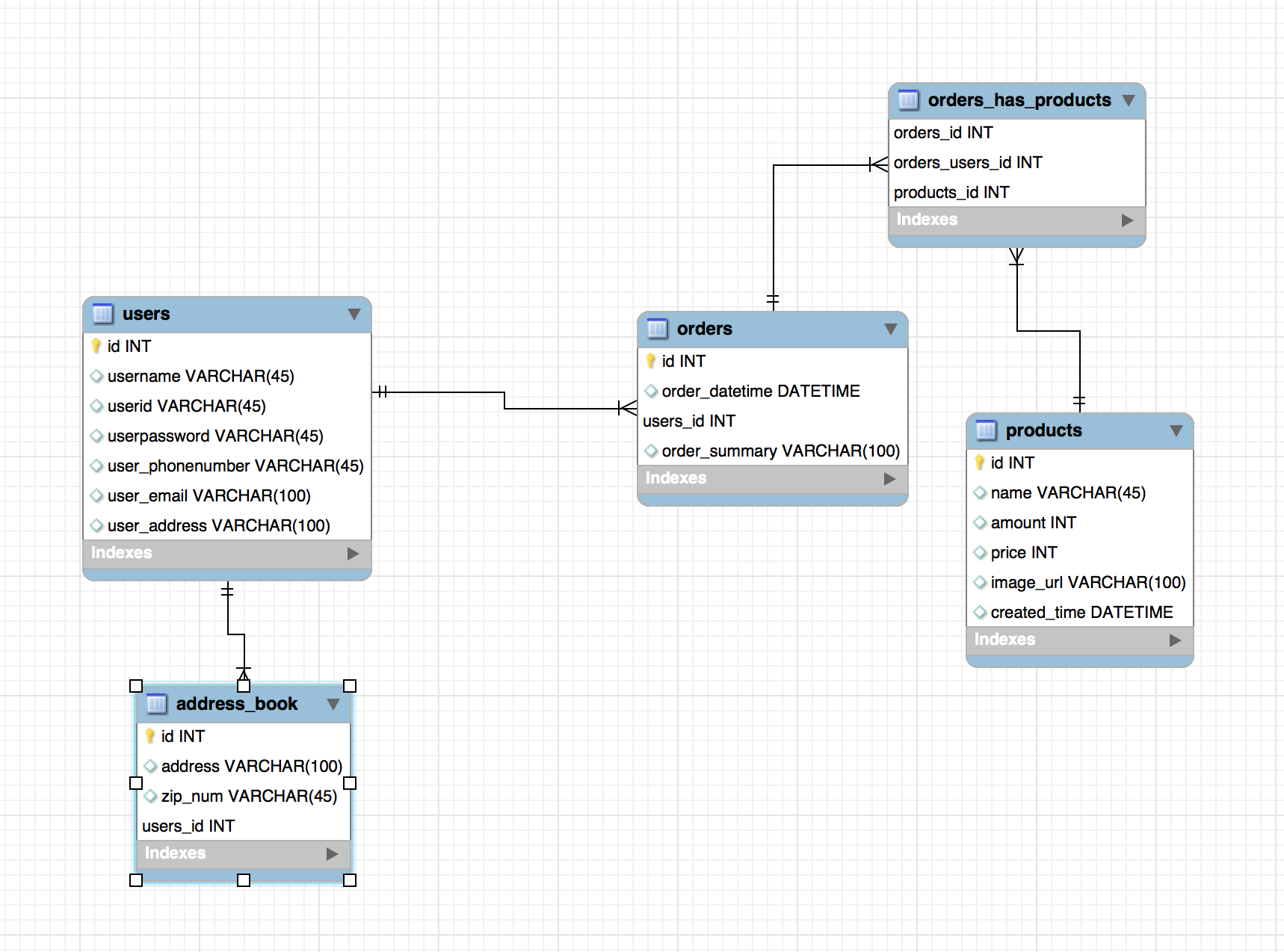
주문을 하기위해서는 유저의 집주소가 필요하다. orders에 users의 address가 있긴 하지만 쇼핑몰에서 주문을 할때 배달장소를 입력받게한다. 이것을 위해 address_book테이블을 추가한다.
-
이제 배송에 관련된 테이블을 추가해야한다. 왜냐하면 우리가 쇼핑몰에서 주문을 하면 한번에 배달받을수도있고 여러개의 상품을 주문했을때는 한 주문을 여러번 나누어서 배송을 받을 수 있다. 그래서 여기에 배송이라는 테이블을 추가해서 address_book과 orders 테이블을 연결한다.
-
이제 장바구니에 등록된 상품들을 배송할 배송지의 정보까지의 설계가 끝낫다. 주문은 결제를 해야 완료된다. 결제를 위한 테이블을 추가하자.
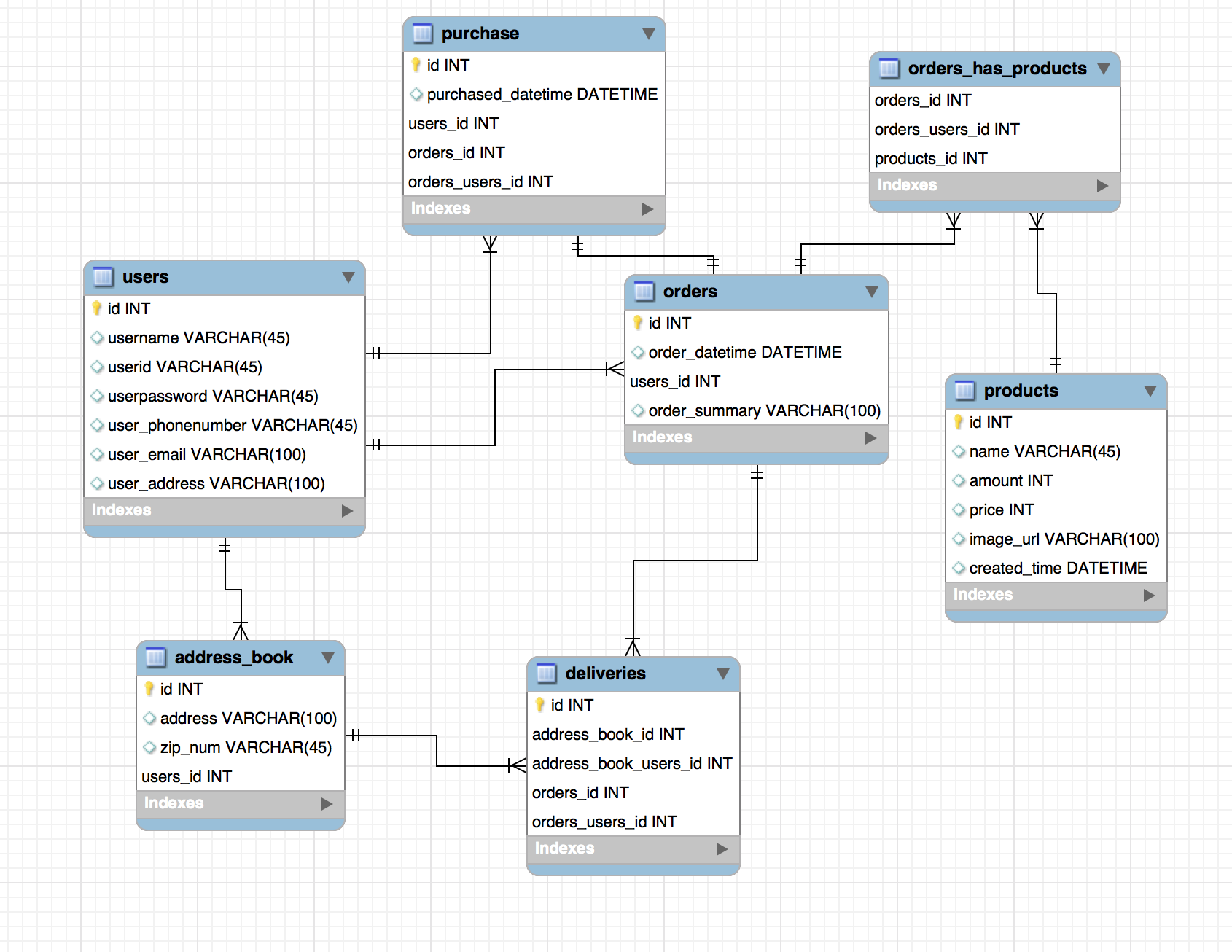
- 결제(purchase)의 테이블을 만들었다. 그런데 여기서 purchase를 보면 유저의 id가 중복이 발생하는 것을 볼 수 있다. orders 역시 유저의 정보를 가지고 잇는데 users와의 관계를 없애도 되지않을까?
- 여기서 users와 orders의 내용의 중복이 purchase에서 발생하기 때문에 purchase에서 users와의 관계를 없애는 것을 정규화 라고한다. 하지만 정규화를 하기전 살펴봐야할 것이 있다. 정규화를 해버리면 사용자가 결제를 하기위해서는 우선 주문테이블을 조회해서 사용자의 id값을 가지고 와야 사용자를 찾을 수 있다. 즉 2번의 조회가 발생한다.
- 서비스의 사용자 수가 많아지면 구매를 할때 2번의 조회가 부담스러워 질 수 있다. 그래서 purchase와 users의 관계를 다시 맺을 수 도 있다. 그럼 1번의 조회로 끝난다. 이걸 역정규화라고 부른다.(성능을 위해 중복을 허용하는 관계를 맺는 것을 말한다.)
- 이것은 전적으로 설계자의 취향과 성능의 문제이므로 정답은 없다.
RDBMS 무결성
- 관계형 데이터베이스 책이라면 어디에서나 나오니 읽어보자.
질문
- ORM에대해서 - 최근에 나온 언어 파이썬, 자바 등등에 ORM이 있는데 DB모델과 상충되는 부분이 있지않은가?
- 보통 스타트업에서 ORM을 많이 사용하는데 (여건이 안되는등의 여러가지 상황때문에) 발표자는 ORM을 되도록 안사용할려고 노력한다.
- 왜냐하면 제작자가 선언 한 것에 따라 자동으로 생성되기때문에 만약 오류가 발생하면 고치기가 쉽지가 않다.
- 예전에 모회사(N 등등..)에서 ORM을 사용하다가 걷어냈다.(데이터의 규모가 커지면 커질수록 ORM을 사용하면 커스터마이징을 할수 없다. 데이터가 커질수록 최적화는 매우 중요한 문제다.)
- ORM을 사용하는 경우는 최대한 빨리 프로토타입을 생성해야할때, 아직 사업의 궤도가 오르지 않앗을때 빨리 만들기 위해 사용하고 사업이 안정화가 되면 걷어내는것이 좋다고 생각한다.(발표자의 기준에서)
- DBMS를 선택하는 기준이 있는가?
- 정답은 아니지만 발표자의 기준은 내가 무엇을 만들것인가에 따라서 선택한다.
- 일반적인 인터넷서비스(티스토리 네이버 카페24) 같은건 Mysql 기준으로 가져간다. 최근에는 라이선스때문에 마리아DB로 바꾸고있다. 상용 DB(오라클 같은)를 쓰는 경우는 프로젝트 비용을 늘려야할 때 사용한다. 클라이언트가 요구하는 경우에 사용 자체적인 서비스를 만들때 오라클을 사용해야하는 기준은 복잡한 프로그램(수십개의 쿼리가 처리되서 나오는 결과 데이터가 완벽해야할때)에 사용한다.
- 다른디비보다 오라클이 좀더 완성도 높은 DB라 성능적인 측면, 데이터에 대한 안정성 측면에서 오라클 만큼의 성능을 내는 DBMS가 잘 없다.
- 발표자는 아직 오라클을 사용할만큼의 무거운 프로젝트를 경험해본적은 없지만 금융권에서 사용한다.
- NoSQL은 데이터에 대해 DBMS가 보장하지않는다(insert ..) 그래서 로그를 쌓는다던가 데이터의 통계를 내야하는 데이터를 쌓아야하는 경우에 사용하지 금융정보나 개인정보같은 것을 저장해야하는 상황에서 사용하면 안된다고 생각한다.(안정성이 보장이 안됨)
- 포스티그리 DB에 ERD도구가 잇나
- 오픈 소스 툴을 위한 ERD관리 도구가 있는건 본적 없다.
- payments테이블에서 orders의 내용과 members의 내용이 중복이 되서 관계를 뺏는데 이 중복을 제거하는 과정을 정규화라고 한다. 결제화면에서 상세결제화면을 보여줄려면 테이블을 2개를 셀렉트해서 만들어야한다.(join을 해도되는데 상식적으로 쿼리를 2개를 날리는것) 그래서 그냥 관계를 만들면 쿼리 1개로 만들 수 있지않느냐?
- 관계가 있을때 쿼리를 2번 날릴것을 1개로 줄이는 장점이 생겼다.
- 정답은 없다. 상황에 마추어서 이런식으로 중복을 허용하는걸 역정규화 라고 한다.
- 데이터베이스 모델링은 절대 정답이 없다. 상황에 맞게, 자신의 생각에 맞게 설계를 한다. 최대한 마음을 열고 설계를 하자
- 정규화란 과정은 필연적으로 데이터베이스의 성능을 낮춘다 그래서 나온것이 역정규화이다. 설계란 정규화와 역정규화의 반복이다.
- Database 성능 관련 책을 봐라( NULL은 index를 안타기때문에 검색과 관련된 테이블을 null을 넣으면 안된다.)
- 볼만한 책
- 대용량 데이터베이스 솔루션 - 엔코아회사 이완식 대표님이 쓰신책
- 오라클 특화된 내용이 많고 어렵다. 하지만 데이터베이스에 관한 내용이 잘담겨져있어서 어떤 DBMS에 대해 잘 설명을 할 수 있다.
- 대용량 데이터베이스 솔루션 - 엔코아회사 이완식 대표님이 쓰신책
Workbench 팁
- 이메일 같이 null이 들어가도 괜찮은 (어른신들은 전화번호만 잇고 이메일은 없을수 잇는) 경우에는 null로 넣지 말고 ‘-‘ 나 기본값을 지정해서 구분하는게 성능적으로 좋을수 있다.
- 데이터베이스 형상관리 팁은 바이너리 파일을 그냥 git에 올리고 ERD 스크린샷을 위키에 같이 올려서 관리하는 경우도 있다.
- 이미 만들어져있는 수십개의 데이터베이스 테이블이 있을때는 그냥 빈 모델을 하나 만들어서 Database의 reverse Engineering을 이용하면 관계를 ERD로 만들어서 보여준다.
- mysql Workbench에서 데이터베이스에 적용 할려면 메뉴 - Database - Synchronized Model을 클릭한다.
- 이건 마이그레이션 툴은 아니기 때문에 싱크로나이즈드 모델을 할 시 문제가 발생할 수있다.(천만개의 데이터가 들어있는 프로덕션 서버에 싱크로나이즈드를 실행하면 문제가 발생할 확율이 높다.)
세미나 후기
- 용영환님께서 매우 즐겁게 세미나를 진행 해주셔서 발표에 집중이 잘되었다.
- 포비가 말했던 왜 ERD를 그리는 과정을 생략해도 상관없는지를 알게되었다. 클래스 설계에 익숙해지면 ERD를 그리는게 자연스럽게 생략되는 것이다.
- 무언가를 만들때 어떻게 접근을 해야하는지 모르겠다면 만들려는 것의 다이어그램을 그려보자.
- UML(Class, 시퀸스 다이어그램)
- ERD(만들려는 것의 데이터를 뽑아내자)
- ERD를 그리는 궁극적 목적은 보다 프로그램에 쉽게 접근을 하기 위해서이다. 내가 만들려는 소프트웨어의 목적과 의도를 개발자가 이해하고 있어야한다는 말이 가슴에 와닿았다. 앞으로 프로그래밍을 할때 좀 더 머리속으로 목적과 의도를 구체화 하고 코딩을 해야겠다.
Comments